Bias in Data Annotation: Causes and Fixes
- The Consensus Trap: Dissecting Subjectivity and the "Ground Truth" Illusion in Data Annotation
- How Manual Annotation Creates Bias
- How Automated Annotation Creates Bias
- Manual vs Automated Annotation: Bias Comparison
- How to Identify Bias in Annotation Processes
- Fixing Manual Annotation Bias
- Fixing Automated Annotation Bias
- How Metamindz Helps with Bias Mitigation
- Conclusion
- FAQs
Bias in Data Annotation: Causes and Fixes
Bias in data annotation is a major headache, whether you're working with manual teams or automated tools. It sneaks in through human subjectivity, skewed datasets, or even flawed algorithms, and the impact can be massive - think mislabelled data leading to AI systems that fail to recognise certain groups or make unfair decisions. For example, facial recognition systems have shown error rates up to 34.7% for darker-skinned women, compared to under 1% for lighter-skinned men. That’s not just a tech issue - it’s a real-world problem.
Here’s the gist:
- Manual annotation introduces bias through human judgement, vague guidelines, and lack of diversity in annotation teams.
- Automated annotation scales errors when trained on unbalanced or poorly labelled datasets.
Fixes? For manual annotation, build diverse teams, set crystal-clear guidelines, and use tools like Inter-Annotator Agreement to catch inconsistencies. For automated systems, focus on diverse training data, add human reviews for tricky cases, and use bias detection algorithms to flag issues early.
The key takeaway: Bias isn’t something you can fully eliminate, but you can manage it with the right strategies. Let’s dig into how to spot and fix these problems step by step.
The Consensus Trap: Dissecting Subjectivity and the "Ground Truth" Illusion in Data Annotation
sbb-itb-fe42743
How Manual Annotation Creates Bias
Manual annotation depends on human judgement, which introduces subjective layers that machine learning models often interpret as objective truth [4][2]. Let’s break down how subjectivity, cultural contexts, and team composition contribute to biases in manual annotation.
Subjectivity and Human Error
Annotators bring their personal and cultural perspectives into the process. For instance, studies using the Stereotype Content Model (SCM) reveal how subjective labelling in face-related tasks often hinges on perceived "warmth" (friendliness) and "competence" (capability). These biases can lead to labels influenced by stereotypes, such as assumptions about someone’s income [3].
When annotation guidelines are vague, annotators tend to rely on their own socio-cultural assumptions to fill in the gaps.
"Bias begins at the brief. Data annotation guidelines often embed assumptions into the dataset. When they're vague or culturally skewed, they quietly sow the seeds of bias,"
says Stacy Ayers, Head of Quality at TrainAI [1].
Language misinterpretation is a common issue as well. Annotators from dominant cultural groups may mislabel African American Vernacular English (AAVE) or regional slang as "negative" or "aggressive" [4][1]. This subjectivity often results in low inter-annotator agreement, where different annotators label the same data point differently, ultimately reducing the accuracy of the model [7].
Cultural and Contextual Biases
Cultural background plays a big role in how annotators interpret behaviour and intent. For example, a phrase considered polite in one culture might come across as rude in another [12]. Even something as simple as interpreting emoji emotions differs - Western annotators often focus on mouth shapes, while Eastern annotators prioritise the eyes [13].
The bias doesn’t stop at sentiment analysis. As of 2025, English dominates nearly 50% of all indexed web content, creating an English-centric slant in annotation practices [13]. Models trained primarily on U.S. English data often struggle when applied to other languages, with F1 scores dropping by as much as 42% and false negatives increasing fourfold [13]. Western-centric guidelines often fail to adapt to the needs of diverse populations [13].
Domain knowledge gaps can also lead to errors. Annotators without local context might misinterpret innocent phrases (like the "Scunthorpe problem") as offensive or fail to recognise medical symptoms that vary across different populations [1].
"When a dataset reflects only one point of view, the models built on it may not take into account or misrepresent entire groups,"
notes Keymakr [12].
Team Homogeneity
Bias doesn’t just stem from individuals - it’s amplified when annotation teams lack diversity. Homogeneous teams tend to reinforce shared perspectives, narrowing the dataset’s scope and embedding cultural assumptions into the data [10]. For example, over two-thirds of workers on major crowdsourcing platforms like Amazon Mechanical Turk identify as white [3].
A study published in September 2024 found that annotator demographics - such as ethnicity and sex - affect both subjective tasks (like inferring personality traits) and objective tasks (like placing bounding boxes) [3]. Without diverse representation, teams are less likely to spot or challenge biases that align with their own backgrounds [8][2].
The consequences are measurable. A NIST study revealed that biases in training data caused some demographic groups to be 100 times more likely to be misidentified by facial recognition systems [4].
"Think of your annotators as the lens through which your model will view the world. A narrow lens leads to narrow insights, so a homogenous annotator pool is likely to inject narrow perspectives," a challenge often addressed by a fractional CTO when building scalable, unbiased tech teams,
explains KnowTechie [10].
How Automated Annotation Creates Bias
Automated annotation might be fast and scalable, but it has a sneaky way of spreading bias across massive datasets. Unlike manual annotation, where human judgement can falter, automated systems stumble when their algorithms or training data have flaws baked in.
Training on Unrepresentative Datasets
Automated systems learn from the data they're trained on. If this initial "seed" data is skewed or incomplete, the algorithm will treat these biases as facts and replicate them across the board. Essentially, bad data in equals bad results out, but at scale [2]. To get quality results from automated annotation, the seed data needs to be fair and diverse. When it’s not, errors snowball, and the system won’t fix itself without human intervention [14].
"Poor training data propagates errors throughout the entire process, creating circular challenges where high-quality annotation requires existing high-quality annotated datasets,"
explains iMerit [14].
Take facial recognition systems as an example. If they're trained on datasets that aren’t diverse enough, the results can be shocking. Some systems have shown error rates up to 34% higher for darker-skinned women compared to lighter-skinned men [16]. This happens because the algorithm favours the majority group in the data, which can lead to discrimination in critical areas like hiring or healthcare [2]. And here’s a staggering stat: around 80% of AI project time is spent on data management and labelling, yet labelling errors can slash model performance by up to 30% [15].
But biased seed data isn’t the only culprit. Automated systems also struggle with overfitting and noise.
Overfitting and Noise Propagation
Automated tools don’t just learn patterns - they memorise them, including all the mistakes. Overfitting happens when these systems latch onto noisy labels, locking in errors and creating inaccurate decision-making boundaries that hurt performance on new data [17].
"If your model is trained on noisy labels, it may overfit to incorrect patterns, leading to poor performance on unseen data,"
warns Amit Yadav [17].
Noise can show up as random errors or systematic mistakes, like consistently mislabelling similar items. Both types of noise drag down model accuracy [17]. For instance, the LabelMe dataset, which uses automated and crowdsourced labels, has an annotator agreement rate of just 0.73, often due to overlapping or unclear label categories [19]. Compare that to the CIFAR-10H dataset, which uses high-quality labels and boasts an agreement rate of 0.92 - a clear sign that lower-quality automated processes bring in far more noise [19].
And then there’s the issue of unsupervised tools, which add their own set of challenges.
Unsupervised Tool Errors
When it comes to ambiguous or nuanced data - like sarcasm, regional slang, or subtle cultural references - unsupervised and semi-supervised tools tend to flounder [2][14]. These systems rely on shortcuts and statistical patterns rather than truly understanding the context, which leads to systematic mislabelling [1]. If they come across data that’s wildly different from what they were trained on, their error rates can skyrocket [14].
To make matters worse, the "black box" nature of many automated tools means it’s tough to figure out how they’re making decisions. This lack of transparency makes it harder for developers to spot and fix the root causes of biased outputs [2].
"If the underlying algorithm is flawed or biased, errors in labelling can propagate throughout the dataset,"
notes Sapien.io [18].
That said, combining AI-powered pre-labelling engines with Inter-Annotator Agreement (IAA) checks can significantly cut down on inconsistencies - by over 85%, in fact [7]. And using AI-driven bias detection tools in annotation workflows can reduce bias-related errors by up to 70% [7]. These steps highlight how essential it is to have solid oversight when using automated annotation systems.
Manual vs Automated Annotation: Bias Comparison
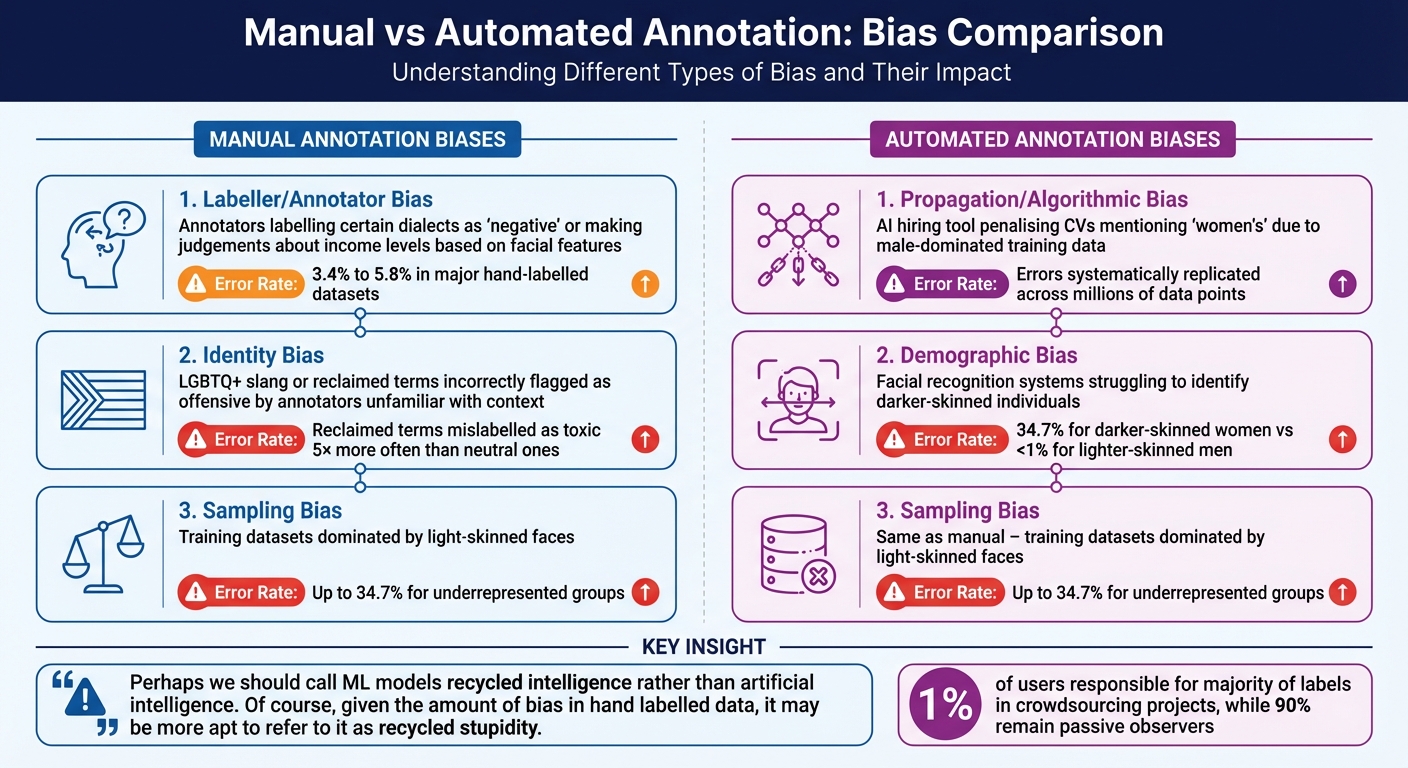
Manual vs Automated Annotation Bias: Types, Examples, and Error Rates
When it comes to bias, manual annotation and automated annotation each have their own pitfalls. Manual annotation is often influenced by the subjective views and personal backgrounds of the annotators, a phenomenon known as labeller bias. This can lead to inconsistencies in the data. For example, even highly regarded datasets like ImageNet have been found to contain a label error rate of around 5.8% [22]. On the other hand, automated annotation tends to amplify initial errors across an entire dataset, a problem referred to as propagation bias [14].
One key difference lies in the nature of their biases. Manual annotation introduces inconsistency because annotators' cultural familiarity and personal interpretations vary. Automated systems, however, apply the same flawed logic uniformly, making their biases more widespread and harder to correct [14].
"Perhaps we should call ML models recycled intelligence rather than artificial intelligence. Of course, given the amount of bias in hand labelled data, it may be more apt to refer to it as recycled stupidity." [22]
Crowdsourcing projects often exacerbate this issue. A small group of contributors can dominate the labelling process, with studies showing that just 1% of users are responsible for the majority of labels, while 90% remain passive observers [20]. This means the dataset can disproportionately reflect the biases of a very small group.
Here’s a breakdown of bias types and their prevalence in manual and automated annotation:
Bias Types and Prevalence
| Bias Type | Examples | Prevalence Rates |
|---|---|---|
| Labeller/Annotator Bias (Manual) | Annotators labelling certain dialects as "negative" or making judgements about income levels based on facial features [3]. | 3.4% to 5.8% error rates in major hand-labelled datasets [22]. |
| Identity Bias (Manual) | LGBTQ+ slang or reclaimed terms incorrectly flagged as offensive by annotators unfamiliar with their context [6]. | Reclaimed terms are mislabelled as toxic 5× more often than neutral ones [6]. |
| Propagation/Algorithmic Bias (Automated) | An AI hiring tool penalising CVs mentioning "women's" due to male-dominated training data [14]. | Errors systematically replicated across millions of data points [14]. |
| Demographic Bias (Automated) | Facial recognition systems struggling to identify darker-skinned individuals [6]. | 34.7% error rate for darker-skinned women compared to less than 1% for lighter-skinned men [6]. |
| Sampling Bias (Manual/Automated) | Training datasets dominated by light-skinned faces, leading to poor recognition of darker skin tones [8]. | Error rates as high as 34.7% for underrepresented groups in unbalanced datasets [8]. |
Both approaches have their challenges. Manual annotation can capture subtleties but suffers from varied biases depending on the annotators. Automated systems, while consistent, often spread their errors far and wide [14]. This comparison highlights the importance of tailoring bias mitigation strategies to the specific annotation method in use.
How to Identify Bias in Annotation Processes
Bias can creep into annotation workflows without notice, jeopardising the reliability of your datasets. To prevent this, you need a systematic approach to uncover and address these biases. By analysing data and applying robust methods, you can spot patterns and inconsistencies before they cause harm.
Statistical Analysis
Statistical tools are a solid starting point for identifying bias. Label distribution analysis helps uncover disparities by using statistical measures like mean, median, and quartiles. For example, if sentiment analysis data consistently labels specific ethnic groups more negatively, it’s a clear sign of bias [2].
To delve deeper, Analysis of Variance (ANOVA) examines whether annotator demographics, such as ethnicity or gender, significantly affect the labels applied [3]. This is particularly relevant given that 66.7% of Amazon Mechanical Turk workers identify as white, which could skew the training data [3].
Other methods, like correlation analysis and metrics such as Intersection over Union (IoU) or Mean Average Precision (mAP), can reveal if stereotypes are influencing labelling decisions. For instance, annotators might unconsciously link traits like "warmth" or "competence" to specific groups, impacting accuracy. Comparing outputs from different annotators can also shed light on subtler inconsistencies.
Consensus Annotation Checks
Cross-checking annotations from multiple annotators can highlight inconsistencies that a single annotator’s work might not reveal. This method is particularly useful for spotting biases caused by unclear instructions or personal prejudices [10][6].
"Disagreement among annotators isn't just noise – it carries valuable information." - Tinkogroup [6]
For instance, annotators unfamiliar with certain cultural contexts might mislabel reclaimed slurs or community-specific slang as toxic up to five times more often than neutral terms [6]. By using Inter-Annotator Agreement (IAA) metrics, you can quantify how much annotators agree and identify areas where cultural gaps or misunderstandings exist.
When annotators clash over labels, don’t dismiss the disagreement. Instead, investigate the root cause - it often reveals biases in the process or dataset [6][24]. For particularly tricky or subjective labels, like those in sentiment analysis, consider routing these cases to expert reviewers. This ensures a more reliable "ground truth" than relying on majority voting [6][10].
Demographic Audits
Demographic audits are invaluable for spotting representation gaps in both your annotators and datasets. These audits can reveal how factors like an annotator’s ethnicity, gender, or cultural background influence their decisions. This is crucial for subjective tasks, such as sentiment analysis, but also for objective ones, like bounding box labelling [3][2].
Auditing your dataset is equally important. For instance, in 2019, ImageNet removed over 500,000 images from its "person" category after identifying systemic biases in its labelling [5]. Regular metadata analysis can help you identify imbalances in both annotators and dataset subjects [23]. Using stratified sampling, you can ensure that key subgroups - based on characteristics like age, gender, or ethnicity - are adequately represented [2].
Fixing Manual Annotation Bias
Dealing with manual annotation bias is all about making practical changes to how your annotation process runs. This type of bias generally comes from human subjectivity, blind spots tied to cultural norms, or inconsistent interpretation of guidelines. To tackle these issues, you’ll need to rethink and refine your workflow.
Build Diverse Annotation Teams
If your annotation team all share similar backgrounds or experiences, you’re likely to end up with results that lean in one direction. To avoid this, aim for diversity. Bring together people with different ages, cultural experiences, and areas of expertise. A mix of perspectives can help uncover hidden biases that might otherwise go unnoticed.
"Individuals from various backgrounds, experiences, and perspectives bring a more nuanced understanding of the data. When a diverse team of annotators collaborate, they can identify and challenge implicit biases that might otherwise go unnoticed."
Before starting labelling, review your annotation briefs with input from this diverse team. They can help spot assumptions that may not apply universally. Another great idea is to hold bias-awareness workshops. These sessions can help annotators recognise their own tendencies and work towards more neutral decisions.
Cross-annotation - where multiple annotators label the same data points - can also help balance out individual interpretations. When disagreements arise, you can work towards a consensus, especially on tricky or ambiguous cases. Research even shows that workflows incorporating balanced representation and review processes can cut bias-related errors by as much as 70% [7].
Once your team is set up, the next step is to focus on creating clear and effective guidelines.
Create Clear Annotation Guidelines
Even with a well-rounded team, unclear guidelines can lead to problems. If instructions are vague, annotators may fill in the blanks with their own assumptions, which can introduce bias. As Stacy Ayers, Head of Quality at TrainAI, aptly puts it:
"Bias begins at the brief. How data annotation guidelines shape AI model behaviour." [1]
To avoid this, craft highly specific guidelines. Make sure they explain the project’s context and clarify the perspective annotators should adopt - whether it’s from the viewpoint of a user, reviewer, or something else. Include a glossary of terms with clear definitions, and set strict inclusion and exclusion criteria. For edge cases, provide step-by-step instructions on what to do, like flagging ambiguous data rather than forcing a decision.
Add example sets to your guidelines, covering both straightforward and tricky scenarios. Include tool walkthroughs with screenshots to show how specific interface elements should be used. Think of your guidelines as a work-in-progress. Annotators should be encouraged to flag confusing areas, and managers should update the rules based on feedback and pilot testing. Running a pilot round with your team can highlight areas of confusion, while embedding "gold sets" (expert-verified examples) ensures ongoing calibration and helps catch hidden biases.
Use Inter-Annotator Agreement Metrics
Inter-Annotator Agreement (IAA) metrics are a great way to measure how consistently your team labels data. Tools like Cohen’s Kappa or Fleiss’ Kappa can give you a sense of whether your annotators are on the same page. High agreement means your guidelines are clear, while low agreement could point to ambiguity or individual biases. By using IAA checks, you can reduce inconsistencies by more than 85% [7].
Start by creating a small "gold standard" dataset of pre-labelled, 100% accurate samples. Use this to benchmark new annotators before they dive into the main task. For subjective tasks, like sentiment analysis, set up a system that flags disagreements for review by a senior team member. Regular calibration exercises - where the team goes over common mistakes or tricky examples - can help keep everyone aligned over time [25].
IAA metrics can also help you spot "annotation shortcuts." These occur when annotators arrive at the same label but for different, and possibly biased, reasons. To prevent this, ask annotators to document which specific guideline they followed for each decision. This way, you can ensure that personal biases aren’t driving their choices.
"Two annotators who agree on labelling a data sample with a particular class might reach the same conclusion by leveraging different guideline definitions. This is in contrast to the main requirement of the prescriptive paradigm, which states that annotators must adhere to the same set of guidelines."
- Federico Ruggeri, Researcher, University of Bologna [24]
Fixing Automated Annotation Bias
Addressing biases in automated annotation requires a combination of human oversight, better data practices, and algorithmic checks. Let’s break down how to tackle this step by step.
Human-in-the-Loop Reviews
Adding human reviews at critical stages is key to catching errors that automated systems might miss. For example, let AI handle routine, straightforward cases while routing trickier, ambiguous, or high-stakes ones to human reviewers. This approach balances efficiency with quality [27].
To avoid biases like automation or anchoring bias, ensure human reviewers make independent decisions before seeing AI-generated outputs. For instance, you could design workflows where humans make an initial judgement before viewing the automated label. As Jacob Beck and colleagues put it:
"Successful human-AI collaboration depends not only on algorithmic performance but also on who reviews AI outputs and how review processes are structured"
[26].
It’s also worth screening reviewers for their scepticism towards AI. Those who approach AI outputs critically are often better at spotting subtle algorithmic errors [26]. Keep track of the "human intervention rate" - how often human input is needed - to measure progress and refine the process over time [27].
Next, let’s talk data diversity, which is another big piece of the puzzle.
Use Diverse Training Data
While human reviews help catch individual mistakes, the root of many systemic biases lies in the data itself. If your training data doesn’t represent all relevant demographics, biases are bound to creep in. A 2018 study found that commercial facial recognition systems had error rates as high as 34.7% for darker-skinned women, compared to less than 1% for lighter-skinned men [6]. Why? Because the training data was skewed.
To fix this, use stratified sampling. Divide your data into groups based on characteristics like gender, age, or ethnicity, and make sure each group is well-represented in your dataset [2]. For example, if you’re building a voice assistant, include accents and dialects from various regions, not just standardised speech.
If certain groups are underrepresented in real-world data, over-sample those minority classes to ensure the model learns them properly [11]. Alternatively, create synthetic datasets that mimic real-world patterns to fill in gaps [2]. Techniques like counterfactual reasoning can also help; this involves identifying "hard negatives" - cases that closely resemble your target class but aren’t - to reduce common misclassifications [21].
Before rolling out large-scale annotations, involve a diverse group of people to audit your guidelines. For instance, if your dataset includes images, bring in reviewers from different backgrounds to flag any potential blind spots. Large Language Models can also help brainstorm tricky edge cases or cultural nuances that might confuse the algorithm [21].
Once your data is in good shape, bias detection tools can help ensure your automated annotations stay on track.
Apply Bias Detection Algorithms
Bias detection algorithms are like a safety net, identifying problematic patterns in automated outputs before they escalate. For example, anomaly and outlier detection algorithms can flag data points that deviate from the norm, which often signals labelling errors or systemic bias [10][7]. Using these tools has been shown to reduce bias-related errors by up to 70% [7].
Another useful approach is active learning pipelines, which focus on "uncertain" or edge-case data points where the model lacks confidence. These cases can then be sent to human reviewers for correction, ensuring that human effort is spent where it’s most needed [7][25].
Consistency scoring is another great technique. By re-annotating data under different conditions, you can measure how reliable the automated labels are. This method has been shown to improve accuracy by over 19% for consistently scored data [28].
Finally, always validate automated labels against a human-labelled "Gold Standard" dataset. This helps identify where the AI diverges from human judgement. Make sure your validation set is diverse too, using stratified sampling to include all relevant subgroups [2]. As Nick Pangakis and Sam Wolken from the University of Pennsylvania note:
"automated annotations significantly diverge from human judgement in numerous scenarios, despite various optimisation strategies such as prompt tuning"
[28].
For an extra layer of quality control, set up a multi-tier pipeline. Start with automated tools for broad labelling, then move to peer reviews, and finish with expert audits. Breaking complex tasks into smaller, manageable chunks can also reduce errors caused by cognitive overload [25].
How Metamindz Helps with Bias Mitigation
When it comes to AI, bias in data annotation is a tricky challenge. Both manual and automated annotation methods can let bias creep in, which is why having sharp technical oversight is crucial. It’s not just about spotting the bias - it’s about understanding how it impacts both the technology and the business. That’s where CTO-led strategies come into play, helping to shape AI systems that are more reliable and fair.
Fractional CTO Services for Bias Mitigation
Metamindz offers fractional CTO services that bring a fresh pair of expert eyes to your AI projects. These services focus on the architecture level, catching bias before it becomes baked into your models. A fractional CTO doesn’t just oversee the process - they actively refine it, introducing frameworks like Human-in-the-Loop systems to keep things on track [29][30].
For instance, they might roll out a five-step pipeline to handle bias. This includes pinpointing where the bias originates (like skewed data sources or annotator demographics), measuring how severe it is, cataloguing it transparently, making it visible to stakeholders, and finally taking corrective action [20]. While bias can’t be completely erased, this method ensures it’s well-managed and clearly understood, empowering teams to make informed decisions.
Another key role of a fractional CTO is to create standardised annotation guidelines based on tested definitions. They also streamline workflows to resolve discrepancies quickly and effectively [4][10]. By involving a diverse group of annotators, they tackle risks like demographic misidentification head-on. And here’s an eye-opener: over 80% of an AI project’s time is spent on data management, including labelling. So, getting this bit right early on isn’t just smart - it’s a huge time and money saver [30].
To complement these bias mitigation strategies, Metamindz also offers a deep-dive technical due diligence service.
Technical Due Diligence for AI Implementations
Beyond just bias checks, Metamindz’s technical due diligence service takes a closer look at the integrity of your AI systems. Whether you’re an investor evaluating a startup or a founder prepping for funding, this service provides a thorough audit of your annotation workflows and AI implementations. At £3,750, it’s a detailed review that covers everything from your codebase to your infrastructure, complete with screenshots and clear evidence of what’s working - and what needs fixing.
This process digs into the nitty-gritty, like auditing your labelling schema (ontology). Poorly defined categories can have ripple effects, such as tanking your SEO or driving up customer churn [11]. The audit also includes segmentation analysis, where datasets are broken down by sensitive attributes to check for performance disparities. As Robyn Speer, Chief Science Officer at Luminoso, aptly puts it:
"Choosing to ignore those choices is still making a choice -- and not necessarily a good one" [32].
What you get isn’t just a list of problems - it’s a roadmap for action. This includes step-by-step instructions, timelines, and documentation that explain the root causes. Metamindz doesn’t leave you hanging either. They schedule calls to help prioritise fixes, and if needed, they can even bring in their own developers to get the job done. As they say:
"We're not just here to identify problems - we help fix them too. If needed, we can also bring in our team of developers to help implement the changes." [31]
For organisations working on high-risk AI systems, this service also ensures compliance with Article 10 of the AI Act. Whether it’s facial recognition software or a voice assistant, a CTO-led audit helps you meet ethical and regulatory standards while building trust in your AI systems.
Conclusion
Bias in data annotation is a challenge that affects both manual and automated processes. Manual annotation often falls victim to cognitive biases, which can be influenced by the demographics of the annotators. On the other hand, automated methods tend to mirror the historical inequalities embedded in their training data and face issues like sampling bias, proxy variables, and negative set bias [5][33][34]. As Maria Mestre aptly states, "Annotation is hard and often leads to the failure of the whole ML project" [11].
Addressing these issues requires a proactive and well-planned approach. For manual annotation, assembling diverse teams, providing clear and detailed guidelines with practical examples, and using consensus checks such as Inter-Annotator Agreement are effective strategies. Automated systems benefit from human-in-the-loop workflows, ensuring that biases are caught and corrected. Even widely used datasets like ImageNet, which has a label error rate of about 5.8%, highlight the need for constant oversight [22].
However, even with these measures, the fight against bias is ongoing. Bias evolves - it shifts with language, societal trends, and new data. This makes continuous attention a necessity. Regular fairness audits, active learning approaches, and real-time quality checks are crucial to maintaining accuracy levels above 99% over a model's lifecycle [7]. As Sigma AI puts it, "Preventing bias requires continuous vigilance - it's a critical operational challenge, not just a technical one" [2].
The role of expert intervention cannot be overstated. Domain experts are essential for resolving ambiguous cases, refining annotation guidelines, and ensuring sensitive areas like healthcare and finance are handled with care [11][9]. Without their input, even the most advanced AI systems risk perpetuating harmful assumptions.
Ultimately, the goal isn't to completely eliminate bias - that's unrealistic. Instead, it's about managing, measuring, and correcting it consistently. By combining expert-led oversight with robust frameworks and technical leadership, we can build AI systems that are both reliable and fair.
FAQs
How can I tell if my labels are biased?
To spot bias in labels, it's crucial to look at how factors like annotator demographics, the clarity of guidelines, and annotation consistency play a role. Bias can creep in if annotations show systematic differences tied to aspects like ethnicity or sex. To minimise this, make sure guidelines are written in a way that’s clear and inclusive, helping to steer clear of embedding any societal biases.
It’s also a good idea to regularly review annotations from a diverse group of annotators. Look for patterns or inconsistencies that might hint at personal opinions or stereotypes influencing the process. Keeping an eye on consistency across annotations is key to ensuring a fair and balanced outcome.
What’s the quickest way to reduce annotator bias?
To cut down annotator bias quickly, the best approach is to create clear, detailed guidelines and bring in a diverse team of annotators. This combination helps maintain consistency and ensures a fairer data annotation process.
When should humans review automated labels?
Humans play a critical role in reviewing automated labels, especially when there's a chance of bias, inconsistency, or ambiguity creeping in. This hands-on approach ensures the data remains accurate and fair while tackling any ethical concerns that might arise during annotation. Regular human oversight isn't just a precaution - it's essential for catching errors and keeping the quality of the labelled data intact.