Bias in Training Data: How to Detect and Fix It
Bias in Training Data: How to Detect and Fix It
When training data is biased, your AI model can end up making unfair or outright harmful decisions. Think of it this way: if you feed your AI flawed data, you’re teaching it to make flawed choices. This could mean anything from rejecting job applications unfairly to misdiagnosing medical conditions. Bias in data isn’t just a tech issue - it can have real consequences for people’s lives.
Here’s the gist:
- Why bias happens: It often sneaks in through how data is collected, labelled, or measured. For example, historical hiring data might reflect past discrimination, and your AI could unknowingly repeat those patterns.
- How to spot it: Look at performance across different groups, visualise data distribution, and analyse model behaviour. Tools like histograms or explainable AI can help uncover hidden issues.
- How to fix it: Use pre-processing (like rebalancing datasets), in-processing (adjusting the training process), or post-processing (tweaking outputs). Each method has pros and cons, so pick what works best for your situation.
- Keep it in check: Regular audits, tracking metrics, and working with diverse teams are key to preventing bias from creeping back in.
The takeaway? Tackling bias isn’t a one-time job - it’s an ongoing process. Whether you’re a startup or a big player, you’ve got to make this a priority. If you’re unsure where to start, bring in fractional CTO support to guide you. After all, the goal is to build AI systems that are fair and reliable for everyone.
3-Step Framework for Detecting and Fixing Bias in AI Training Data
How Bias in Training Data Destabilizes AI Decisions
sbb-itb-fe42743
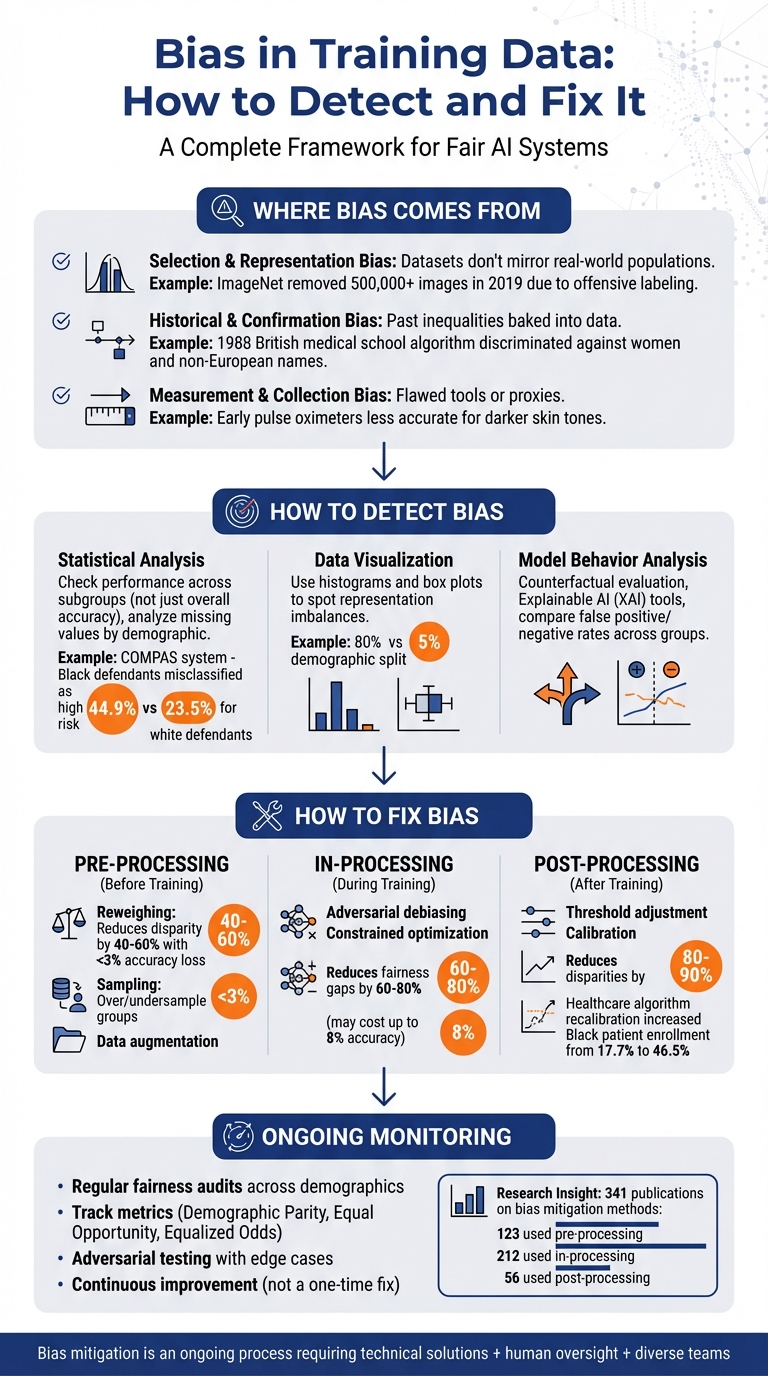
Where Bias in Training Data Comes From
Bias sneaks into AI systems through various pathways, including how data is collected, labelled, and measured. Pinpointing these sources is key to addressing the problem effectively. This process is often a core component of a technical due-diligence assessment for AI-driven companies.
Selection Bias and Representation Bias
Selection bias happens when a dataset doesn’t mirror the real-world population the AI is meant to serve. This can occur when certain groups are over-represented or completely left out. For example, surveys that exclude mobile-only users can lead to skewed results [2]. A striking case is ImageNet, a widely-used AI dataset, which removed over 500,000 images from its "person" category in late 2019. This action came after the "ImageNet Roulette" project exposed that the system was tagging individuals with offensive terms [3]. Another issue is negative set bias, where a lack of counterexamples limits the AI’s ability to differentiate effectively [3].
Historical and Confirmation Bias
Historical bias reflects inequalities baked into past practices. A classic example is using data from discriminatory lending practices to train modern credit models [2]. Confirmation bias, on the other hand, occurs when data collection or labelling reinforces existing beliefs [2]. Label bias can creep in when annotators classify the same item differently based on subjective views [3]. A historical example: in 1988, a British medical school’s shortlisting algorithm was found to discriminate against women and applicants with non-European names. Why? It had been trained on decisions rooted in historical biases [3].
Measurement and Data Collection Bias
Even if sampling and labelling are done carefully, bias can still arise from flawed tools or proxies. Measurement bias can result from human error, faulty devices, or using inaccurate stand-ins for what’s being measured [3].
For example, early pulse oximeters were less accurate for people with darker skin tones. These devices were calibrated using light absorption data from lighter skin, which led to systemic diagnostic errors for Black patients [1].
Similarly, relying on proxies like arrest rates as a measure of crime rates can build systemic bias into the model [3].
Next, we’ll dive into methods for spotting these biases before jumping into how to fix them.
How to Detect Bias in Training Data
Spotting bias in your training data is crucial to ensure your AI model doesn’t inherit or amplify unfair patterns. It’s not as simple as looking at overall metrics - bias often lurks beneath the surface, in the details that aggregate figures can hide.
Statistical Analysis and Fairness Metrics
The first step is to analyse performance across subgroups instead of relying solely on overall accuracy. For example, your model might boast a 95% accuracy rate overall, but what if it drops to 70% for a specific demographic? That’s a clear warning sign that something’s off [4].
You should also dig into missing values. Are certain features consistently absent for specific groups? This could point to under-representation. For instance, if income data is frequently missing for a particular age bracket, that’s worth investigating [4]. Another thing to watch for is proxy variables - features like postcodes or education levels that might unintentionally stand in for sensitive attributes like race or socioeconomic status [4]. And don’t forget to check for bias amplification. If your model predicts outcomes for certain groups at rates higher than those found in the training data, it’s exaggerating the imbalance rather than reflecting reality [5].
Visualising Data Distribution
Numbers tell part of the story, but visuals often make problems jump off the page. Tools like histograms and box plots can give you a quick read on representation issues. Imagine a histogram showing 80% of your dataset is from one demographic, while only 5% represents another. That’s a glaring imbalance [4]. Box plots, on the other hand, can help you spot outliers or unusual feature values - potential signs of errors in data collection or systemic inaccuracies [4].
Visualisation can also uncover patterns in missing data. If certain characteristics are consistently absent for specific subgroups, it’s a strong indicator of under-representation [4]. These patterns are easy to overlook without a visual aid.
Model Behaviour Analysis
Understanding how your model behaves under different conditions can reveal hidden biases. Techniques like counterfactual evaluation and explainable AI (XAI) tools can show how changes to social attributes (like gender or ethnicity) influence outputs [6] [1]. If small changes in these attributes lead to wildly different results, you’ve got a problem.
Take the COMPAS system as an example. ProPublica’s 2016 investigation found that Black defendants were twice as likely as white defendants to be misclassified as high risk for reoffending (44.9% versus 23.5%). Meanwhile, white defendants were more often misclassified as low risk [1] [3]. This is a textbook case of disparate impact analysis, where false positive and false negative rates are compared across groups to identify bias in model predictions.
How to Fix Bias in Training Data
Once you've identified bias in your data, the next step is tackling it with the right methods. These usually fall into three categories: pre-processing (modifying data before training), in-processing (embedding fairness during model training), and post-processing (adjusting outputs after training). The choice depends on your resources, pipeline structure, and fairness goals.
Pre-Processing Techniques
Pre-processing addresses bias at its root by tweaking the data itself, leaving algorithms or models untouched. One effective method is reweighing, which adjusts the significance of training examples based on their sensitive attributes and labels. For instance, if a dataset underrepresents a specific group, reweighing gives those examples more weight during training. This approach has been shown to reduce demographic disparity by 40% to 60%, with less than a 3% dip in accuracy [7].
Another handy technique is sampling. This could mean undersampling overrepresented groups, oversampling underrepresented ones, or even using tools like SMOTE to create synthetic examples for minority groups [8]. Similarly, data augmentation involves creating new data points by swapping protected attributes (like gender) in existing records, which can be a lifesaver for smaller datasets [9].
For more complex challenges, Learning Fair Representations (LFR) is an option. This method transforms data into a new format that hides sensitive attributes while keeping task-relevant information intact [7]. Tools such as IBM AI Fairness 360 (AIF360) and Fairlearn include built-in algorithms for these types of adjustments [7].
If pre-processing alone doesn’t cut it, you might need to dive into fairness during training or tweak outputs after the model is built.
In-Processing and Post-Processing Approaches
In-processing methods weave fairness into the training process itself. A popular technique is adversarial debiasing, which penalises the model when sensitive attributes can be inferred from its internal data. Another option is constrained optimisation, like applying fairness constraints to logistic regression, balancing fairness and accuracy during training [7]. These methods can reduce fairness gaps by 60% to 80%, though they may cause accuracy to drop by as much as 8% [7].
"In-processing methods offered the strongest fairness improvements on parity and error rate fronts, but at a higher accuracy cost and implementation complexity" [7].
On the other hand, post-processing focuses on adjusting a trained model’s outputs. This approach is ideal for cases where retraining isn’t feasible, like when working with third-party models. Techniques include threshold adjustment, which sets different decision cut-offs for different groups, and calibration, ensuring probability predictions are fair across subgroups [7]. Post-processing solutions, such as equalised odds thresholding, can cut disparities by 80% to 90% with minimal impact on the model’s structure [7]. That said, Raghavan cautions:
"Post-processing offers flexibility but risks per-group distortions and lacks transparency" [7].
A great example of post-processing in action comes from a 2019 study. Researchers, led by Ziad Obermeyer, analysed a U.S. healthcare risk-prediction algorithm used for 43,539 White patients and 6,079 Black patients. The algorithm relied on "healthcare costs" as a proxy for health needs, which skewed risk scores against Black patients. By recalibrating the algorithm to use direct health indicators (like chronic condition counts), they nearly tripled the enrolment of high-risk Black patients in care programmes, boosting their representation from 17.7% to 46.5% [10]. This shows how small adjustments can drive massive change.
For the best results, a hybrid approach - combining pre-processing with in-processing - can strike a good balance between fairness and accuracy [7]. A review of 341 studies found that 123 used pre-processing, 212 relied on in-processing, and 56 applied post-processing, with several employing multiple methods [8]. The trick is to pick the approach - or mix - that aligns with your goals and limitations.
But let’s not forget: technical fixes alone won’t cut it. Human oversight is just as crucial.
Collaborate with Domain Experts
Bias in AI often stems from human bias - our historical views and assumptions seeping into the data. That’s why expert input is essential to spot and correct subtle or evolving biases. Research highlights:
"Human bias is the dominant origin of biases observed in AI; it reflects historical perceptions and assumptions that can manifest at any stage of development" [10].
Domain experts can identify "concept shift", where the meaning of data or outcomes changes over time, and help interpret those shifts. For example, a 2023 study of healthcare AI models revealed that half had a high risk of bias, while only 20% were deemed low risk [10].
Diverse teams also make a huge difference. By bringing in a mix of perspectives, they can challenge ingrained assumptions and reduce bias.
"Development teams with greater diversity are consistently better at reducing their own bias by bringing multiple perspectives to their teams" [9].
Such teams usually include data scientists, domain experts (like doctors for healthcare models), institutional stakeholders, and members of the affected population [10].
If you don’t have in-house expertise, partnering with a tech firm like Metamindz could be the way forward. They offer tailored solutions, from auditing your data to implementing bias mitigation techniques, all while integrating these fixes into your existing systems.
Another option is seeking external bias audits. Independent professionals can evaluate your processes and set up ongoing monitoring to ensure fairness across demographics. Bias reviews should cover the entire lifecycle - from data collection to post-deployment [10].
Maintaining Fair AI: Monitoring and Auditing
Ensuring fairness in AI systems isn’t a one-and-done task. Biases can creep in over time as data evolves, user behaviour shifts, or unexpected edge cases emerge. This makes continuous monitoring an absolute must - fairness has to be baked into every stage of the AI lifecycle, not just during its initial development.
Regular Fairness Audits
Regular audits are your best defence against hidden biases. These reviews go beyond just measuring overall accuracy; they require digging deeper into how the system performs for different groups. For example, breaking results down by demographics like age, gender, or location can reveal disparities that might be hidden in aggregate metrics. A model might boast high accuracy overall but still underperform for minority groups, and that’s a problem [1].
Start by identifying sensitive attributes like race, gender, or age, as well as any proxy variables - things like postcodes, which can sometimes indirectly reflect socioeconomic status or ethnicity [3]. From there, you can run a disparate impact analysis to compare outcomes (like approval or error rates) across different groups [1].
Adversarial testing is another powerful tool. This involves feeding your model edge-case data from underrepresented groups to see how it holds up. Standard tests often miss these vulnerabilities, so adversarial testing is crucial for spotting biases that only appear in specific scenarios [1].
For a more structured approach, you might want to explore AI Impact Assessments (AIIAs). These assessments help you identify potential societal or ethical risks both before and during deployment [1]. Transparency is key here too - tools like Datasheets for Datasets can document where your data comes from, its intended uses, and any known limitations [3]. Such documentation creates an audit trail, making it easier to track and address performance shifts over time.
Tracking Fairness Metrics
To fix fairness issues, you first need to measure them. Keeping an eye on fairness metrics over time helps you spot when things start to go off course. Some commonly used metrics include:
- Demographic Parity: Ensuring equal outcome proportions across groups.
- Equal Opportunity: Ensuring equal true positive rates.
- Equalised Odds: Balancing true and false positive rates.
- Predictive Parity: Making sure precision is consistent across groups [1].
However, these metrics often clash with one another. For example, optimising for Demographic Parity might make it impossible to achieve Predictive Parity. These trade-offs aren’t just mathematical - they’re ethical decisions that depend on the specific context of your AI system [1].
"AI systems are not impartial arbiters but rather reflections, and often exaggerations, of the data upon which they are built." - MedTech News [1]
To stay on top of things, set up dashboards that monitor these metrics regularly. Look for patterns - if performance for a particular subgroup starts slipping, dig into the why and address it quickly.
Continuous Improvement Practices
Fairness isn’t a one-time fix; it’s an ongoing effort. Regular audits and metric tracking are a great start, but you also need practices that ensure your system keeps improving.
One effective technique is subtractive labelling. Instead of redoing all your labels, focus on the ones the model is struggling with - low-confidence outputs. Have human annotators refine or remove incorrect labels. This targeted approach improves recall and helps catch errors that the model might otherwise perpetuate [11].
Another handy method is greyscale testing. Train a greyscale version of your model alongside the full-colour version. This can help you spot if the model is over-relying on colour cues instead of focusing on the actual context - a common source of bias. In one study, a labelling workflow where team members specialised in specific categories resulted in a 3.4% improvement in object detection compared to generalist teams [11].
To keep these efforts sustainable, consider bringing in external expertise if needed. For instance, a partner like Metamindz, led by a CTO, can provide hands-on oversight, regular reviews, and fairness checks throughout your AI’s development lifecycle. This kind of partnership can be invaluable if in-house resources are limited.
Conclusion: Building Better AI with Bias-Free Data
Key Points Recap
Creating fair AI systems isn’t a one-and-done task - it’s an ongoing effort that spans the entire lifecycle of your AI models. We’ve covered a range of strategies, from spotting selection and historical biases in your data to applying techniques like pre-processing, in-processing, and post-processing. These approaches set the stage for responsible AI, but the real challenge begins once your models are live. Regular monitoring, subgroup audits, and iterative fixes are vital to keeping your systems fair as new data and unexpected scenarios come into play.
To give you some perspective, in-processing techniques can narrow fairness gaps by 60–80%, while post-processing methods can achieve reductions of 80–90% [7]. The field of bias mitigation is thriving, with a survey identifying 341 publications dedicated to these methods [8].
"ML algorithms, which are never designed to intentionally incorporate bias, run the risk of replicating or even amplifying bias present in real-world data." - ACM Survey [8]
These strategies are bolstered by partnerships with experts who bring a wealth of experience to the table.
The Role of Expert Partners
Addressing bias in AI isn’t just about technical fixes - it requires a mix of skills across AI, data science, ethics, and policy. Let’s face it: not every team has all these bases covered in-house [3]. That’s where expert partners come in, bridging the gap between theoretical knowledge and practical application.
For instance, a CTO-led partner like Metamindz can provide the technical leadership needed to ensure fairness at every stage of your AI project. Whether it’s reviewing your system’s architecture, auditing your code, or conducting ongoing fairness checks, these experts help you stay compliant with regulations and aligned with ethical standards. Their guidance ensures your AI systems remain robust, transparent, and, most importantly, fair.
FAQs
Which fairness metric should I use for my model?
When it comes to fairness in machine learning models, there’s no one-size-fits-all metric. The best choice depends entirely on the context of your model and the fairness goals you’re aiming for. Some commonly used metrics include demographic parity, equal opportunity, and equalised odds. These metrics help evaluate fairness by looking at how your model performs across different subgroups.
The key is to align your choice of metric with the specific needs and objectives of your use case. For example, if you're working on a hiring algorithm, you might prioritise demographic parity to ensure equal representation. On the other hand, in scenarios like credit scoring, equal opportunity might be more relevant to ensure fairness in positive outcomes. Always tailor the metric to what fairness means in your particular situation.
How can I identify hidden proxy variables in my data?
To spot hidden proxy variables, start by examining how features correlate with sensitive attributes like race, gender, or age - even when these attributes aren’t directly part of the dataset. Take a close look at the data collection process to check for any unintended biases that might have crept in. Techniques such as subgroup analysis, feature importance evaluation, or sensitivity analysis can be incredibly useful for identifying features that might be having an outsized impact on outcomes. Pairing these statistical approaches with insights from domain experts can make it easier to pinpoint and address these proxies in a meaningful way.
When should I use pre-, in-, or post-processing to reduce bias?
When working with machine learning models, there are three main stages where you can address biases: pre-processing, in-processing, and post-processing. Each tackles bias at a different point in the workflow.
- Pre-processing: This step focuses on modifying the training data itself before the model is trained. It's handy when your dataset has issues like missing values or isn't representative of the problem you're trying to solve. For example, if your dataset underrepresents a particular group, you can balance it out here.
- In-processing: This happens during the training phase. It involves adding fairness constraints or tweaking the learning process to reduce biases in how the algorithm learns. This is the go-to method when the bias stems from the way the model processes the data.
- Post-processing: Once the model is trained, post-processing comes into play. It adjusts the outputs of the model to ensure they align with fairness metrics. This is useful when biases are only identified after training is complete.
Each of these approaches has its strengths, and often, combining them can lead to better results. For instance, you might clean up the data (pre-processing), adjust the training process (in-processing), and then fine-tune the outputs (post-processing) to create a more balanced and fair model.