Context Engineering Is What Separates AI Agents That Work from Expensive Demos

Context Engineering Is What Separates AI Agents That Work from Expensive Demos
Context engineering is the practice of designing and managing the full information architecture that an AI agent receives at inference time - including retrieved data, tool outputs, conversation history, system instructions, and memory - to reliably produce the right behaviour in production. It has replaced prompt engineering as the defining discipline for teams building AI agents that actually work beyond a demo.
So.. I've spent the last six months watching engineering teams throw money at AI agents. Building them, deploying them, watching them fail spectacularly in production, then quietly shelving them. The pattern is always the same: brilliant demo, impressive pitch deck, production deployment that hallucinates its way through customer data within 48 hours.
The problem isn't the model. It almost never is. The problem is what you're feeding it.
According to Datadog's 2026 State of AI Engineering report, 69% of companies now use three or more models alongside increasingly complex agent workflows. Agent framework adoption has doubled year-over-year. And yet, 5% of all LLM call spans in production report errors, with 60% of those caused by rate limits alone - before you even get to the quality failures nobody's logging.
The teams that are actually shipping reliable agents? They've stopped obsessing over which model to use and started obsessing over context.
What Context Engineering Actually Means (And Why Prompt Engineering Won't Cut It Anymore)
Prompt engineering is about finding the right words. Context engineering is about building the right information architecture. That distinction matters enormously when you're running agents that make 50+ tool calls per task, as Manus reported is their average.
The numbers make this concrete. DataHub's 2026 State of Context Management Report found that 82% of IT and data leaders agree prompt engineering alone is insufficient to power AI at scale. 95% of data teams plan to invest in context engineering training this year. And 89% plan to invest in context management infrastructure within the next 12 months.
This isn't a rebrand. It's a fundamental shift in what engineering teams spend their time on. Prompt engineering asks: "What's the best way to phrase this instruction?" Context engineering asks: "What's the full configuration of information that will most reliably produce the behaviour I need?"
That includes system prompts, yes. But also: what tools are available, what their schemas look like, what conversation history is retained, what external data is retrieved, how tool outputs are formatted, what gets summarised versus kept raw, and what gets thrown away entirely.
| Dimension | Prompt Engineering | Context Engineering |
|---|---|---|
| Focus | Wording of instructions | Full information architecture at inference |
| Scope | Single interaction | System-level, across agent lifecycle |
| Key concern | Phrasing and formatting | What information is included, excluded, and when |
| Optimisation target | Response quality for one query | Reliable behaviour across thousands of runs |
| Token strategy | Minimal consideration | KV-cache optimisation, cost per inference |
| Failure mode | Bad output on edge cases | Cascading errors across multi-step workflows |
| Skill required | Good writing, some LLM intuition | Systems thinking, data architecture, observability |
Why Your AI Agent Works in the Demo and Dies in Production
I've done technical due diligence on a dozen startups this year that had AI agents "in production." Most of them had the same failure pattern: the agent worked brilliantly on the 10 scenarios the team tested during development, then fell apart on scenario 11.
The root cause, nearly every time, was context management. Specifically, one of two failures that Anthropic's engineering team identified: including content irrelevant to the current step, or excluding content that matters.
This sounds simple. It isn't. Because the compound nature of errors in agentic systems means a minor issue at step 3 sends the agent down an entirely different trajectory by step 8. One wrong tool output left in the context window, one piece of stale conversation history, one retrieval result that's technically relevant but practically misleading - and the whole chain unravels.
Manus, one of the more impressive agent platforms I've seen, has rebuilt their agent framework four times. Each time, the breakthrough wasn't adding something clever. It was removing something that was polluting the context. Their team calls this iterative process "Stochastic Graduate Descent" - and I think that's the most honest description of AI agent development I've heard.
The Four Patterns That Actually Matter
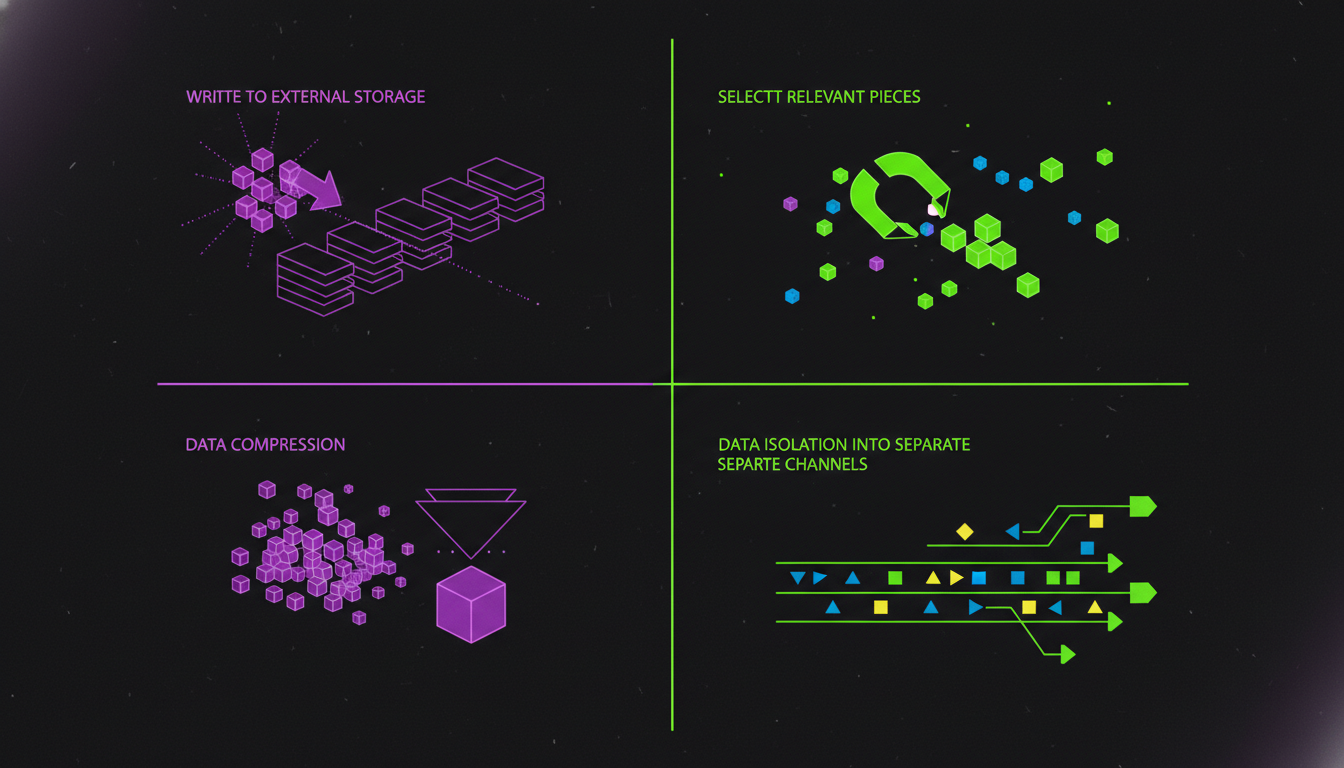
After working with multiple engineering teams on AI agent adoption, I've found that context engineering boils down to four operations. Every technique, every framework feature, every architectural decision maps to one of these:
1. Writing context - saving information outside the context window for later retrieval. This is your agent's long-term memory. File systems, databases, vector stores - anything that persists beyond the current inference call. The key insight: your agent should be actively deciding what to save, not passively accumulating everything.
2. Selecting context - pulling the right information into the context window at the right time. This is where RAG lives, but it's broader than RAG. It includes deciding which tools to expose (too many tools is a common failure mode), which conversation history to include, and which retrieved documents actually answer the current question versus just matching some keywords.
3. Compressing context - retaining meaning while reducing token count. Summarisation, deduplication, extracting structured data from verbose tool outputs. Manus found that their average input-to-output token ratio is 100:1. That means 99% of computational cost goes to processing context. Even small compression gains compound massively at scale.
4. Isolating context - preventing different concerns from contaminating each other. Multi-agent architectures do this naturally by giving each sub-agent its own context window. But even within a single agent, you need boundaries. The common mistake of dumping a shared transcript into every sub-agent means every agent reads everything, inherits everyone else's mistakes, and pays the same context bill repeatedly.
The One Metric Most Teams Aren't Tracking (But Should Be)
If you're running AI agents in production and you're not tracking your KV-cache hit rate, you're flying blind on both cost and latency.
KV-cache is how LLM providers avoid recomputing attention for tokens they've already processed. When your context window has a stable prefix - same system prompt, same tool definitions, same recent history - the provider can cache those computations and charge you dramatically less.
How dramatically? With Claude Sonnet, cached input tokens cost $0.30 per million versus $3.00 for uncached. That's a 10x cost difference based purely on how you structure your context. Same model, same output quality, 10x cheaper. Or 10x more expensive if you're reorganising your context unnecessarily between calls.
This has direct architectural implications. It means you want stable, predictable context prefixes. It means you should append new information at the end of the context rather than inserting it in the middle. It means you should think about your system prompt, tool definitions, and base instructions as a cached foundation that rarely changes, with dynamic content layered on top.
Most teams I advise discover they're paying 3-5x more than necessary for their agent infrastructure once they start optimising for cache hits. That's not a marginal improvement. That's the difference between an economically viable product and one that bleeds cash.
Why RAG Alone Won't Save You
I need to address the elephant in the room. A lot of teams think "context engineering" means "build a better RAG pipeline." It doesn't.
DataHub's research found that 77% of IT and data leaders agree that RAG alone is insufficient for accurate and reliable AI deployments in production. The problem isn't retrieval. The problem is that retrieval is only one of many sources of context, and most teams treat it as the only lever they can pull.
I've seen agent systems where the RAG pipeline returns perfectly relevant documents, but the agent still fails because:
- The tool output format is verbose and buries the answer in irrelevant metadata - The conversation history includes 15 turns of failed attempts that bias the model toward the same mistakes - The system prompt gives vague high-level guidance instead of concrete decision criteria - Too many tools are exposed, creating ambiguous decision points about which tool to use
Context engineering means treating ALL of these as design decisions, not afterthoughts. As Anthropic put it: context is a compiled view over a richer stateful system. It's not a bag of documents you throw at a model. It's a carefully assembled representation of everything the model needs to know right now, and nothing it doesn't.
What I Tell Engineering Teams to Do (Concretely)
When I work with teams on AI agent adoption at Metamindz, context engineering is now the first thing we address. Not model selection, not framework choice, not prompt tuning. Context architecture. Here's the practical playbook:
Start with context auditing. Before you optimise anything, instrument your agent to log exactly what goes into the context window at each step. Most teams are shocked by what they find - duplicated information, stale history, tool outputs that are 10x longer than they need to be. You can't fix what you can't see.
Design your tool schemas for the model, not for humans. Your agent's tool outputs should be as clean and structured as possible. If a tool returns a 500-line JSON blob but the agent only needs 3 fields, transform the output before it hits the context window. Every unnecessary token costs money and dilutes the signal.
Implement aggressive conversation history management. Not every turn matters. Implement summarisation for older turns, keep recent turns in full, and have clear rules about when to truncate. The agent processing a customer's tenth question doesn't need verbatim transcripts of questions one through seven.
Use context isolation for multi-step workflows. If your agent has distinct phases - planning, execution, validation - each phase should get a tailored context. The execution phase doesn't need the raw brainstorming from the planning phase. It needs the plan.
Optimise for KV-cache from day one. Structure your context with a stable prefix. System prompt first, tool definitions next, then dynamic content. Avoid reshuffling the order between calls. This single decision can cut your inference costs by 50-80%.
Treat context like a production system. Version your prompts. Monitor your context window utilisation. Set alerts for when context size exceeds thresholds. Track cache hit rates. Context is infrastructure, not prose.
| Practice | What Most Teams Do | What Works (CTO-Led Approach) |
|---|---|---|
| Tool output handling | Pass raw API responses to the model | Transform and extract only relevant fields before context |
| Conversation history | Keep full transcript until token limit | Summarise old turns, keep recent turns verbatim |
| System prompts | Vague guidance ("be helpful") | Concrete decision criteria with examples |
| Tool exposure | Give agent access to everything | Expose only tools relevant to current phase |
| Cost tracking | Monthly bill review | Per-inference cost tracking with KV-cache monitoring |
| Context debugging | Read model outputs when things break | Log full context snapshots, trace failures to specific context |
| Multi-agent context | Share everything with every agent | Isolate contexts, pass only structured handoff data |
Why This Matters for Your AI Adoption Strategy
If you're a CTO or engineering lead evaluating AI agent adoption, context engineering should be front and centre of your technical strategy. Not model selection. Not which framework to use. Those matter, but they're second-order decisions.
The SDG Group's analysis of the shift from prompt engineering to context design found that organisations investing in context quality and AI-ready metadata are seeing materially better outcomes from their AI initiatives. The teams spending their budget on prompt engineering consultants and model switching are treading water.
This is exactly why our AI adoption work at Metamindz starts with a context architecture review, not a tool recommendation. We've built AI agents for clients - including MintyAI, a complex bookkeeping system with AI workflows - and the single biggest factor in delivery speed and production reliability was getting context engineering right early.
When we built MintyAI in 2 weeks (versus an estimated 4-5 months traditionally), it wasn't because we used a magic model. It was because we designed the context architecture before writing a line of agent code. Every tool output was shaped for the model. Every workflow phase had isolated context. Every piece of retrieved data was relevant and fresh.
If you're a fractional CTO or technical lead trying to figure out where to start with AI agents, start here. Audit your context. Instrument your token usage. Track your cache hit rates. The model will do what you need it to do if you give it the right information at the right time.
Frequently Asked Questions
What is context engineering for AI agents?
Context engineering is the practice of designing, curating, and managing the complete information architecture that an AI agent receives at inference time. It includes system prompts, tool definitions, conversation history, retrieved data, and memory - everything the model uses to make decisions. Unlike prompt engineering, which focuses on phrasing instructions, context engineering treats the entire information pipeline as a system to be architected and optimised.
How is context engineering different from prompt engineering?
Prompt engineering optimises the wording of instructions to an LLM. Context engineering optimises the full set of information the model receives, including prompts, tool outputs, retrieved documents, conversation history, and memory. According to DataHub's 2026 report, 82% of data leaders agree prompt engineering alone is no longer sufficient for production AI systems. Context engineering is a systems-level discipline, not a writing exercise.
Why do most AI agents fail in production?
Most AI agent failures trace back to context management problems: including irrelevant information that confuses the model, or excluding critical information it needs. Because agents make sequential decisions, errors compound - a minor context issue at step 3 can send the agent down an entirely wrong path by step 8. Datadog's 2026 report found 5% of all LLM production calls return errors, with context-related quality failures likely even higher but harder to measure.
What is the KV-cache hit rate and why does it matter for AI costs?
KV-cache hit rate measures how much of your context window can be reused between inference calls without recomputation. With Claude Sonnet, cached tokens cost $0.30 per million versus $3.00 uncached - a 10x difference. By structuring context with stable prefixes (system prompt, tool definitions) and appending dynamic content at the end, teams typically reduce agent infrastructure costs by 50-80%.
How should a startup approach context engineering for AI agents?
Start by instrumenting your agent to log exactly what enters the context window at each step. Audit for duplicated information, oversized tool outputs, and stale conversation history. Design tool schemas that return only what the model needs. Implement conversation history summarisation. Optimise for KV-cache from day one. Treat context as production infrastructure with monitoring, versioning, and alerts - not as an afterthought.